前言
Bun install 命令安装依赖包的速度堪称极致,平均而言,它比 npm 快 7 倍,比 pnpm 快 4 倍,比 yarn 快 17 倍。这种速度优势在依赖众多的大型前端工程中会体现的非常明显,其安装耗时直接从分钟级干到毫秒级。

它能达到这个效果的核心原因在于它针对安装过程中的每个环节都做了极致性的设计和实现,包括优化系统调用,消除 javascript 开销,异步 dns 解析,二进制 Manifest 缓存,优化 tarball 提取,利于缓存的数据结构设计,锁文件格式的优化,文件复制过程的优化以及多核利用的并行化处理等,笔者读完之后叹为观止,感受到了其做底层基建的匠心,特意翻译并分享出来。
在正式介绍优化手段前,需要先介绍一个概念 - 系统调用
系统调用
什么是系统调用
软件程序无法直接与计算机的硬盘,网络等打交道,我们的代码每次在执行一些操作(诸如文件读写,网络连接,分配内存)时都需要调用操作系统的能力来实现,这称之为系统调用。
系统调用会带来什么问题
计算机的 CPU 可以在两种模式下运行程序,一种是用户模式,一种是内核模式。
我们的应用代码主要在用户模式下运行,这种模式下的程序无法直接访问计算机的硬件,物理内存,主要是防止程序相互干扰致使系统崩溃。
内核模式则主要是应用于系统内核的运行,用于管理资源,例如调度进程,驱动 CPU、处理内存以及磁盘或网络设备等硬件。只有内核和设备驱动程序才可以在该模式下运行!
当我们的代码在执行系统调用时,CPU 会进行模式切换,模式切换时,CPU 会经历停止执行程序 → 保存其所有状态 → 切换到内核模式 → 执行操作 → 然后切换回用户模式的过程。这个模式切换的成本比较高,单次切换就需要耗费 1000-1500 个 CPU 周期。
这是什么概念呢?在 3G Hz 处理器上,1000-1500 个周期大约是 500 纳秒。这个时间听起来可以忽略不计,但现代 SSD 每秒可以处理超过 100 万次操作。如果每个操作都需要进行系统调用,那么仅模式切换就需要 15 亿个周期。
依赖包安装的过程会进行数千次系统调用。像 React 这种大型库及其依赖项甚至可能会触发 50,000+ 次的系统调用,意味着仅模式切换就消耗了几秒的 CPU 时间!这还不包括读取文件或安装软件包的耗时。
针对不同包管理器做系统调用的 benchmark 测试,如下所示:
1 | Benchmark 1: strace -c -f npm install |
Bun 的安装速度最快,它的系统调用最少。对于一个简单的安装,yarn 有超过 400 万次的系统调用,npm 接近 100 万次,pnpm 接近 500k,bun 165k。
Bun 之所以能做到这一点,离不开它在细节处的臻于完美。
消除 javascript 开销
npm, pnpm, yarn 均采用 Node.js 编写,在 Node.js 中调用 fs.readFile 读取文件时,会经过一个复杂的管道,包括:
- JavaScript 验证参数并将字符串从 UTF-16 转换为 UTF-8,以适配于 libuv 的 C API。这个转换过程会在任何 I/O 启动之前短暂阻塞主线程。
- libuv 将该处理请求加入到 4 个工作线程的处理队列中。如果当前无空闲线程,则请求将持续等待。
- 工作线程拾取请求,打开文件描述符,并进行实际的
read()系统调用。 - CPU 切换到内核模式,从磁盘获取数据,并将其返回到工作线程。
- 工作线程通过事件循环将文件数据推送回主线程,最终规划和执行你的回调。
每个 fs.readFile() 调用都会经过此管道。包安装过程会涉及数千个 package.json 文件的读取,包括:扫描目录、处理依赖项元数据等。每次线程调度时(例如,在访问任务队列或向事件循环发出信号时),可以使用 futex 系统调用(Fast Userspace Mutex, Linux 内核提供的一种基础同步机制,用于实现高效的锁和同步原语。它结合了用户空间操作的快速性和内核空间阻塞的可靠性,是现代多线程编程的核心组件)来管理锁或等待。
数千次这种复杂的管道执行带来的系统调用开销相当高昂。而 Bun 是用 Zig 语言(对标 rust 的另一种系统编程语言)编写的,可编译为具有直接系统调用访问权限的本机代码。
1 | // Direct system call, no JavaScript overhead |
当 Bun 读取文件时,Zig 代码直接进行系统调用,内核立即执行系统调用并返回数据,中间没有任何 javascript 引擎解析,线程池,事件循环等处理流程,性能差异不言而喻。
| Runtime | Version | Files/Second | Performance |
|---|---|---|---|
| Bun | v1.2.20 | 146,057 | |
| Node.js | v24.5.0 | 66,576 | 2.2x slower |
| Node.js | v22.18.0 | 64,631 | 2.3x slower |
在此基准测试中,Bun 每秒处理 146,057 个 package.json 文件,而 Node.js v24.5.0 处理 66,576 个,v22.18.0 处理 64,631 个,快了 2 倍多!
Bun 基本没有任何运行时负担,每个文件的 0.019 毫秒就代表了其实际的 I/O 开销。而基于 Node.js 编写的包管理器由于 Node.js 本身的运行时解析成本和底层抽象成本,相同的读文件操作就需要耗费 0.065 毫秒。
异步 DNS 解析
安装依赖意味着需要处理网络请求,从 registry 上拉取依赖包信息,这就需要获取 registry.npmjs.org 等域名的 IP 地址。
对基于 Node.js 编写的包管理器来说,执行 dns 解析主要通过 dns.lookup() 方法来实现,这个方法看似异步,实则其内部实现为 getaddrinfo() 方法的调用,在 libuv 的线程池上运行时仍然会阻塞子线程。
在 macOS 系统上 Bun 采用了 Apple 提供的一个隐藏异步 dns 查询 API - getaddrinfo_async_start(), 这个 API 并不在 POSIX 标准之中,它可以使用 mach 端口(Apple 的进程间通信方式)实现完全异步运行的 dns 解析请求。
这个优化仅针对 macOs 系统。
二进制 Manifest 缓存
在正式安装依赖包之前,包管理器会先下载依赖包的 manifest 文件(内容包括这个包的版本记录,依赖项和元数据等),对于一些像 React 这种具有 100+ 版本的流行包,其 manifest 文件大小可能会达到几兆大小。以 lodash 为例,其 manifest json 文件内容如下所示:
1 | { |
对于包管理器来说,这种 manifest 描述文件的问题在于每次安装依赖包时,即使通过缓存的手段避免了文件的再次加载,但依然需要解析该 json 文件,除了语法验证,ast 构建,gc 管理等解析本身的开销以外,还有大量的内存冗余消耗问题。以上述的 lodash 为例,字符串 Lodash modular utilitie, https://lodash.com/,git+https://github.com/lodash/lodash.git 重复出现在每个版本中。在 json 解析时,js 会在内存中为每个字符串都创建一个单独的字符串对象,这就导致了有很多重复的内存分配。
Bun 解决这个问题的方式为通过二进制格式来存储 manifest 描述。当下载 manifest 文件时,它会解析一次 JSON 将其存储为二进制文件(~/.bun/install/cache/ 中的 .npm 文件),并将所有包信息(版本、依赖项、校验和等)存储于特定的字节偏移量中。
当 Bun 访问名称 Lodash modular utilitie 时,它只是进行指针的算数运算:string_buffer + offset,没有任何的 json 解析,对象遍历和内存分配。
1 | // Pseudocode |
benchmark 测试下显示即使是缓存下的 npm install 也比无缓存的 Bun 安装要慢。
1 | Benchmark 1: bun install # fresh |
Tarball 提取
在处理完 manifest 描述文件后,包管理器会从 registry 上下载并提取 tarball 文件(即压缩的存档文件,如 .zip 文件,其中包含每个包的实际源代码和文件)。
大多数包管理器通过流式传输来接收 tarball 文件数据,并在接收到数据时进行解压缩,整个过程从一个小缓冲区开始,随着更多解压缩数据的到来,缓冲区会被填满,此时会再分配一个更大的缓冲区,然后复制所有当前数据,再循环往复这个过程。
1 | let buffer = Buffer.alloc(64 * 1024); // Start with 64KB |
这种处理逻辑看似合理,但会带来性能瓶颈:当缓冲区反复超出当前大小时,会出现多次复制拷贝相同数据的情况,举例来说,假设我们有一个 1M 大小的包,按照上述逻辑会经历以下步骤:
- 初始化 64kb 大小的缓冲区
- 填写 → 分配 128KB → 复制 64KB
- 填写 → 分配 256KB → 复制 128KB
- 填写 → 分配 512KB → 复制 256KB
- 填写 → 分配 1MB → 复制 512KB
整个过程重复的复制了多达 960kb 的数据,而且每个安装包都会出现这种 case。
Bun 的处理方式则是在解压缩之前就缓冲整个 tarball,而不是在数据到达时才进行处理。它能做到这点是因为在 Zig 中可以直接查找到 tarball 文件的最后 4 个字节,这 4 个字节中存储了文件的未压缩大小,因此 Bun 可以预先分配内存。
1 | { |
而基于 Node.js 编写的包管理器很难做到这一点则是因为它需要单独创建一个读取流,一直搜索到最后,读取到那 4 个字节之后解析它们再关闭流,然后重新开始解压缩,这么做会比流式传输更慢。
缓存友好的数据结构
在安装依赖包时,由于大多数包都有自己的依赖,且这些依赖还会有自己的依赖,就会形成一个比较复杂的图关系结构。包管理器必须遍历该图以检查包版本、解决版本冲突并确定要安装的版本,部分依赖项还需要进行”提升(hoist)”,以便多个包可以共享它们。传统的包管理器存储依赖项的数据结构如下:
1 | const packages = { |
在 js 中,对象存储在堆上,当访问 packages[“next”] 时,CPU 会访问一个指针,该指针告诉它 Next 的数据在内存中的位置。然后,此数据包含指向其依赖项所在位置的另一个指针,而该指针又包含指向实际依赖项的更多指针,如下图所示。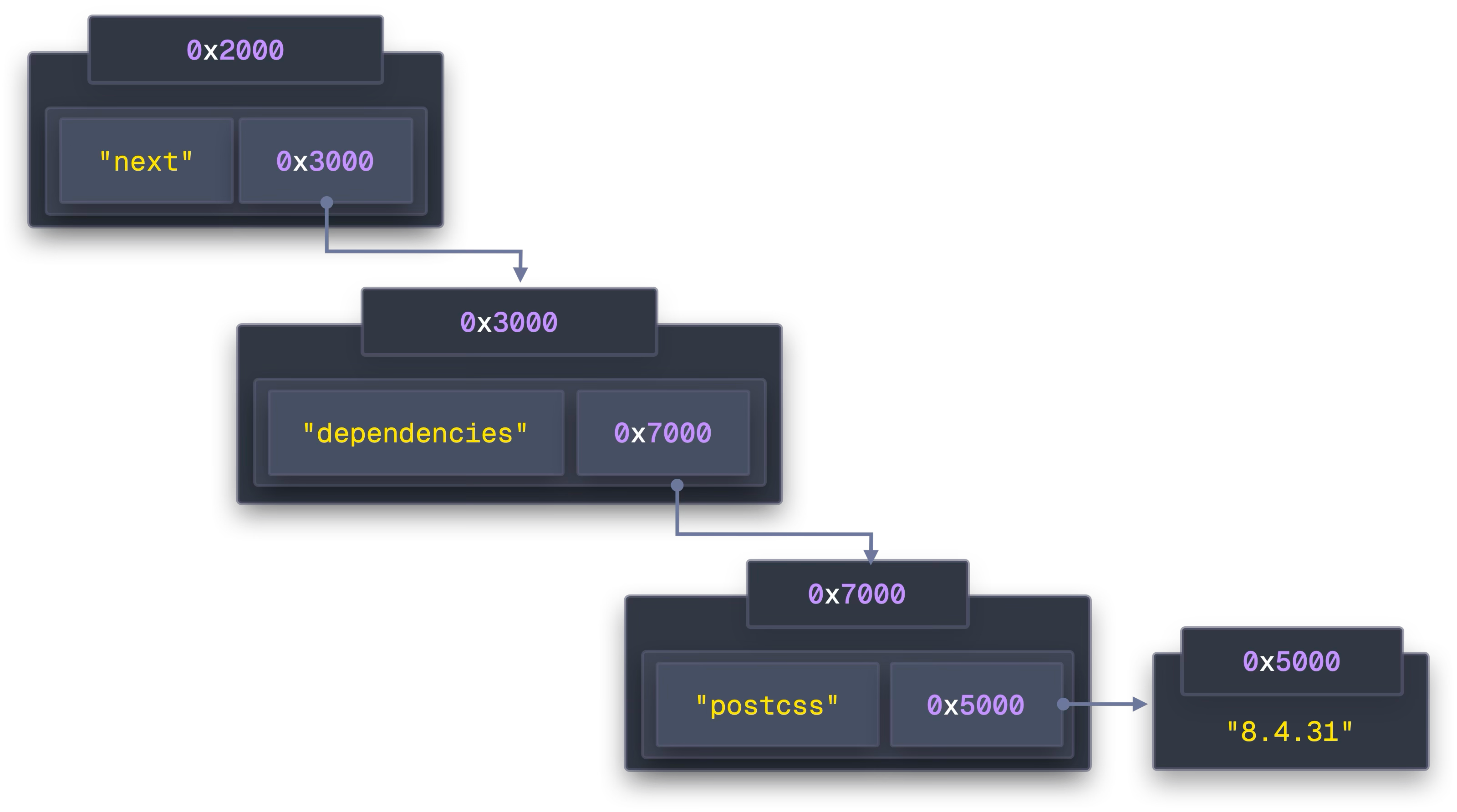
在不同时间创建对象时,javascript 引擎会使用当时可用的任何内存:
1 | // These objects are created at different moments during parsing |
这些内存地址非常随机,没有任何局部性保证,对象可以随意分散在 RAM 中,即便是彼此有关联的对象!这种方式与现代 CPU 的取数机制背道而驰。
现代 CPU 处理数据的速度极快(每秒数十亿次运算),但从 RAM 获取数据的速度却很慢,为了弥补这一差距,CPU 实现了多级缓存:
- L1 缓存,32kb,但速度极快(~4 个 CPU 周期)
- L2 缓存,256kb,稍慢(~12 个 CPU 周期)
- L3 缓存,8-32MB 存储,需要 ~40 个 CPU 周期
- RAM:大 GB 空间存储,需要 ~300 个周期
当进行内存访问时,CPU 会加载该内存地址以及该地址后的整个 64 字节块,CPU 会认为如果你访问了一个字节,那么你可能很快就会用到其附近的数据,这称之为空间局部性。但这种机制非常适合按顺序存储的数据,像上面那种随机分配的内存地址则会适得其反。
当 CPU 在地址 0x2000 处加载 packages[“next”] 时,它实际上加载了该缓存行中的所有字节。但是下一个包 packages[“postcss”] 位于地址 0x8000 。这是一条完全不同的缓存线!CPU 加载在缓存行中的其他 56 字节完全被浪费了,它们只是附近恰好分配的任何东西的随机内存;也许是垃圾,也许是不相关对象的一部分。
当访问 512 个不同的包(32KB / 64 字节)时,L1 缓存会被填满。后续每个新的包访问都会逐出以前加载的缓存行以腾出空间。这样刚刚访问的包很快就会被逐出,缓存命中率下降,每次访问就都变成了 ~300 个周期的 RAM 行程,而不是 4 个周期的 L1 命中。
在遍历 Next 的依赖项时,CPU 必须执行多个依赖的内存加载:
- 加载 packages[“next”] 指针 → 缓存未命中 → RAM 获取(~300 个周期)
- 按照该指针加载 next.dependencies 指针 → 另一个缓存未命中 → RAM 获取(~300 个周期)
- 按照它在哈希表中找到 “postcss” → 缓存未命中 → RAM 获取(~300 个周期)
- 按照该指针加载实际字符串数据 → 缓存未命中 → RAM 获取(~300 个周期)
仅读取一个依赖项名称,就是 ~1200 个周期(在 400GHz CPU 上为 3ns),如果有 1000 个依赖包,每个包平均有 5 个依赖项,这就是 2 毫秒的纯内存延迟。
Bun 则采用了数组结构来存储所有的依赖项,将所有包名称保存在一个共享数组中:
1 | // ❌ Traditional Array of Structures (AoS) - lots of pointers |
- packages 存储轻量级的结构体,结构体中使用偏移量来指定依赖包数据查找的位置。
- dependencies 将所有包的实际依赖关系存储在一个地方
- string_buffer 将所有文本(名称、版本等)按顺序存储在一个大字符串中
这种数据结构下,再访问 Next 的依赖项就变成了纯算数运算:
packages[0]告诉我们 Next 的依赖项从 dependencies 数组中的位置 0 开始,并且有 2 个依赖项:{ name_offset: 0, deps_offset: 0, deps_count: 2 }- 转到
dependencies[1],它告诉我们 postcss 的名称从字符串 string_buffer 中的第 34 位开始,版本在第 42 位开始:{ name_offset: 34, version_offset: 42 } - 转到 string_buffer 中的第 34 位并阅读 postcss
- 转到 string_buffer 中的位置 42 并阅读 “8.4.31”
这样一来,由于 CPU 会加载整个 64 字节的缓存行,每个包是 8 个字节,当你访问 packages[0] 时,你可以在单个内存获取中通过包[7] 获得包[0]。当 Bun 处理 react 依赖项(packages[0]、packages[1] 到 packages[7] 时,它们就已经位于 L1 缓存中,无需额外申请内存即可访问。这就是顺序访问如此之快的原因:只需访问一次内存即可获得 8 个包。相比传统的基于对象嵌套结构的包管理器而言,可谓颇具优势。
锁文件处理
大多数包管理器将锁文件存储为嵌套的 json(如 npm 的 package-lock.json) 或者 yaml(pnpm, yarn) 文件,当 npm 解析锁文件时,它也需要解析这种深度嵌套的对象。
1 | { |
这就会面临跟前面一样的内存随机分配的问题,Bun 在锁文件的处理上也应用上了上述的数组结构优化。同时,Bun 也复用了 tarball 文件优化的手段,前置读取锁文件大小并预先分配内存。
文件复制
当依赖包完成安装并缓存在对应目录下后,包管理需要将文件复制到 node_modules 中。传统的文件复制方式是遍历每个目录并单独复制文件,这个过程会涉及多次系统调用:
- 打开源文件
- 创建和打开目标文件
- 从源重复读取块并将它们写入目标,直到完成
- 最后,关闭两个文件
对于一个典型的具有上千个依赖包文件的 React 应用程序来说,系统调用的次数会高达数十万到数百万次。
Bun 解决这个问题的方式是利用不同操作系统的特性,采用不同的复制策略。
macOS 系统
在 macOS 上,Bun 使用 Apple 原生的 clonefile() API 执行复制操作,该 API 可以在单个系统调用中克隆整个目录树。它的方式是创建新的目录和文件元数据来存放原缓存中依赖包数据的引用,而不是完全的数据拷贝和写入。
1 | // Traditional approach: millions of syscalls |
1 | Benchmark 1: bun install --backend=copyfile |
cloneFile 的方式明显更为高效,且 Bun 也实现了兜底策略,当 cloneFile 执行失败时,Bun 会回退到 clonefile_each_dir 以进行每个目录的克隆。如果这也失败了,Bun 使用传统的复制文件作为最终的兜底。
Linux
在 Linux 下,Bun 采用了硬链接的方式进行优化。硬链接不创建文件,仅为现有文件创建新名称并引用该文件。创建一个硬链接仅需一次系统调用,且与源文件大小无关。这种方式由于没有移动数据,性能提升和磁盘空间利用的效果非常显著。但这种方式也并非稳定有效,可能会有文件系统不支持或者权限配置导致创建失败的问题。
但 Bun 还有后招:
- ioctl_ficlone, 该方法支持在 Btrfs 和 XFS 等文件系统上进行写时复制(copy-on-write)。这与 macOs 下的 clonefile 的写时复制非常相似,它也创建了共享相同磁盘数据的新文件引用。
- copy_file_range, 如果写时复制不可用,Bun 会回退到 copy_file_range 方法。该方法下,内核从磁盘读取到缓冲区再到直接写入磁盘,数据移动只需两个操作和零上下文切换。而传统方式下,调用 write 方法进行写入时,会在写入磁盘前将数据再复制回缓冲区,这就是 4 个操作和多个上下文切换的成本。
- 如果上述方法均不可用,Bun 会使用
sendfile方法,该方法最初为网络传输而设计,但它在两个文件间复制传输数据也很高效。 - copyfile, 这是最后的手段,即传统的文件复制方式,也与大多数包管理器的实现方式一致,同时也是最低效的方式。
1 | Benchmark 1: bun install --backend=copyfile |
Bun 在不同系统下采用了不同的优化手段最大程度上减少了文件复制带来的系统调用开销,堪称极致。
多核并行
传统的包管理器基于 Node.js 编写,尽管 Node.js 拥有一个线程池,但在安装依赖包过程中,所有实际工作都运行在一个线程和一个 CPU 内核上,在现代多核 CPU 架构上明显会有资源闲置。
Bun 采用的是一种无锁,无闲置的线程池架构,空闲线程会从繁忙线程中拾取待处理任务,当一个线程完成一项工作后,它会检查其工作队列,如果没有剩余任务,则从其他线程中取活儿干,可谓一刻不停歇的顶级牛马。
Bun 的线程池会自动扩展以匹配设备的 CPU 核心数量,使其可以最大限度的并行化安装过程中的 I/O 密集型部分。
但多线程最大的问题就是数据竞争,传统实现下,每次单个线程想要添加任务到共享队列时,都必须先添加锁,避免其他线程写入。Bun 采用了无锁数据结构,它使用了一种原子化操作的特殊 CPU 指令,允许线程在没有锁的情况下可以安全修改共享数据。
1 | pub fn push(self: *Queue, batch: Batch) void { |
此外,为了避免多线程同时争夺内存分配,Bun 还为每个线程分配了单独的内存池,线程可以独立管理这些内存,无需共享或等待。
总结
Bun 深度挖掘了依赖包安装过程中的每个细节,并尽可能做到了极致的优化。整个过程令我受益匪浅,不积跬步无以至千里,尽管 AI 浪潮汹涌,但底层的基础设施仍需关注和精心打磨。
参考
若你觉得我的文章对你有帮助,欢迎点击上方按钮对我打赏
扫描二维码,分享此文章