
前言
Grab 是东南亚领先的超级应用平台,总部位于新加坡,业务覆盖 8 个国家 500 余城市。其核心业务模式是通过移动应用整合多元生活服务,具体包括:出行,外卖配送,金融等。
在数字服务领域,从用户提交的电子文件(如身份证、驾驶证、注册证书等)中准确提取信息,是客户识别等流程的关键第一步。在东南亚地区,由于语言和证件格式的多样性,使得这项任务尤其具有挑战性。
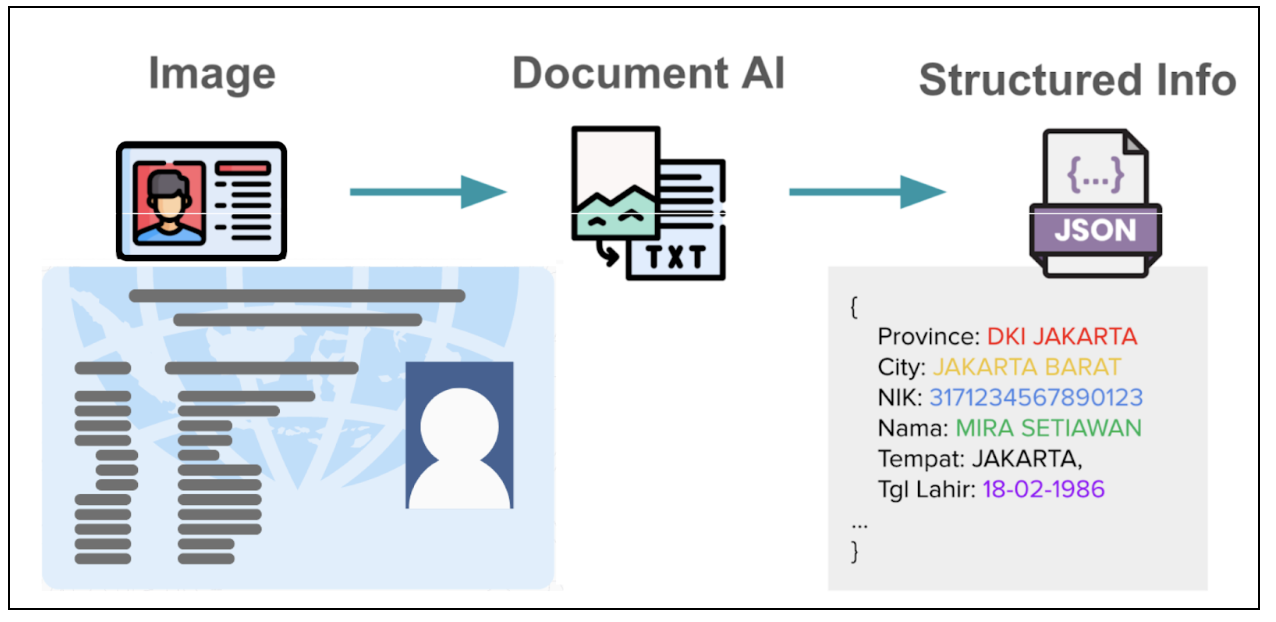
传统的 OCR 技术难以应对这种证件模板的多样性,尽管业界也有一些专有大模型,但它们通常在理解东南亚语言方面表现欠佳,且存在错误,幻觉以及高延迟等问题。此外,开源的多模态视觉大模型在准确度上也还难以达到生产环境的要求。
于是 Grab 选择对现有模型进行微调,并最终从头开始开发了一个轻量级、专业化的视觉大语言模型,本文梳理了全过程以及 Grab 在实践中得出的一些关键结论和洞察,这也是 AI 解决实际业务问题的又一经典案例。
关于视觉模型
什么是视觉模型
与普通大语言模型不同的是,视觉大语言模型可以理解图像,其基础架构主要包括以下三个部分:
- 图像编码器:主要作用是将图片的图元数据转化为向量化的数值格式。
- 视觉-语言投影器:主要作用是充当跨模态翻译器,将图像的数值化特征转换为语言模型可理解的特征表示。
- 语言模型:接收转化后的图片特征表示和文本作为输入,输出模型处理后的结果,类普通的大语言模型。
整体的输入输出流程示意图如下所示: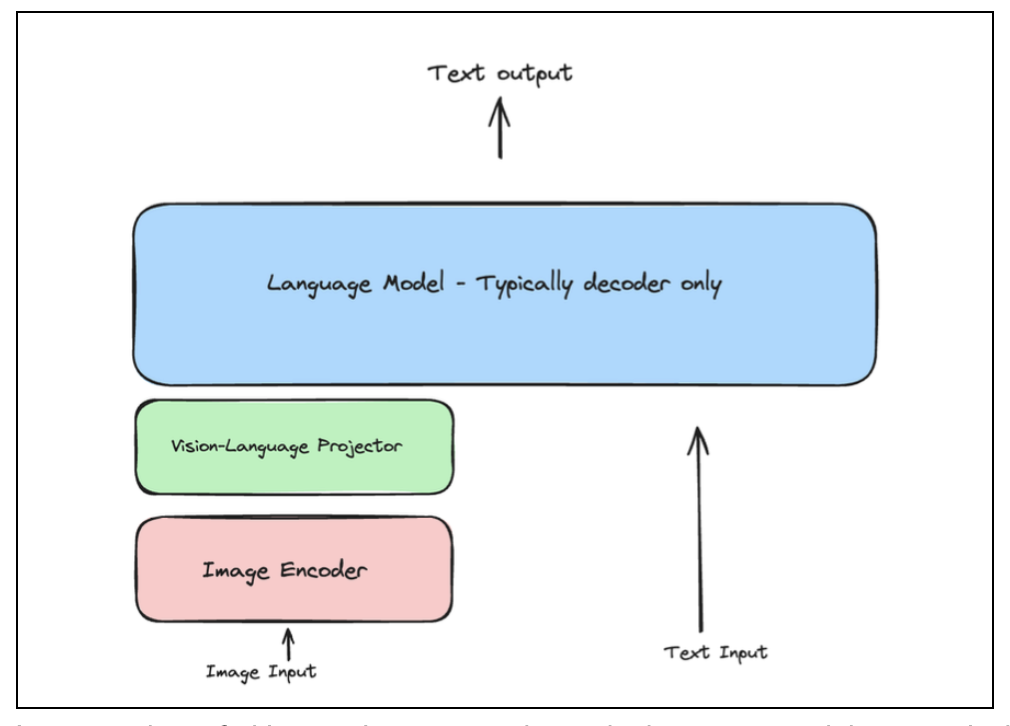
基座视觉模型的选择
Grab 评估了多款具备 OCR 与关键信息提取(KIE)能力的大语言模型。通过对开源方案的深入测试—包括 Qwen2VL、miniCPM、Llama3.2 Vision、Pixtral 12B、GOT-OCR2.0 和 NVLM 1.0——最终选定 Qwen2-VL 2B 作为基础多模态大模型,该决策基于以下关键因素:
- 高效的模型尺寸:模型体积足够小,可在显存资源有限(VRAM-limited)的 GPU 上实现全参数微调。
- 东南亚语言支持:分词器对泰语、越南语等语言处理高效,表明其原生词汇覆盖度良好。
- 动态分辨率处理:与要求固定尺寸输入的模型不同,Qwen2-VL 可直接处理原始分辨率图像。该特性对 OCR 任务至关重要,可避免因图像缩放/裁剪导致的文本字符变形问题。
Grab 基于已有数据集对 Qwen2-VL 和 miniCPM 进行了基准测试。初步结果显示准确率较低,主要源于东南亚(SEA)语言覆盖不足。因此,需要对模型进行微调,以提升 OCR 和 KIE(关键信息提取) 的准确率。
训练大语言模型是数据密集型且 GPU 资源密集型的过程,在具体实施前需解决两大关键问题:
- 数据,如何有效利用开源和内部的相关数据来训练模型。
- 模型,如何自定义模型以达到高精度和低延迟的效果。
准备训练数据集
合成 OCR 数据集
首先从大型在线文本语料库——Common Crawl(互联网开放数据集)中提取东南亚语言文本内容。然后通过内部合成数据流水线,将东南亚语种文本内容以多样化字体、背景及图像增强技术渲染生成文本图像,数据集包含印尼语、泰语、越南语及英语等语言的文本图像,每张图像对应一个随机句子段落,如下图所示:
Documint: AI 驱动的自动标注框架
实验证明,文档检测与方向校正能显著提升 OCR 与信息提取准确率。在获得 OCR 数据集后,需进一步生成预处理数据集以优化模型训练。
Grab 内部自主研发了一个名为 Documint 的面向文档理解的自动标注与预处理框架,可生成高质量标注数据集。该系统通过多个子模块协同执行完整的 OCR 与 KIE(关键信息提取)任务:
基于 Grab 海量卡证文档构建处理流水线,通过人工审核员精校标签数据确保高精度,Documint 系统包括四个部分:
- 检测模块:从整图中定位文档区域
- 方向校正模块:返回旋转校正角度(如文档倒置时输出180°)
- OCR 模块:输出非结构化文本
- KIE 模块:将非结构化文本转化为结构化JSON(如提取{“姓名”:”张三”,”电话”:”138xxxx”})
示意图如下所示: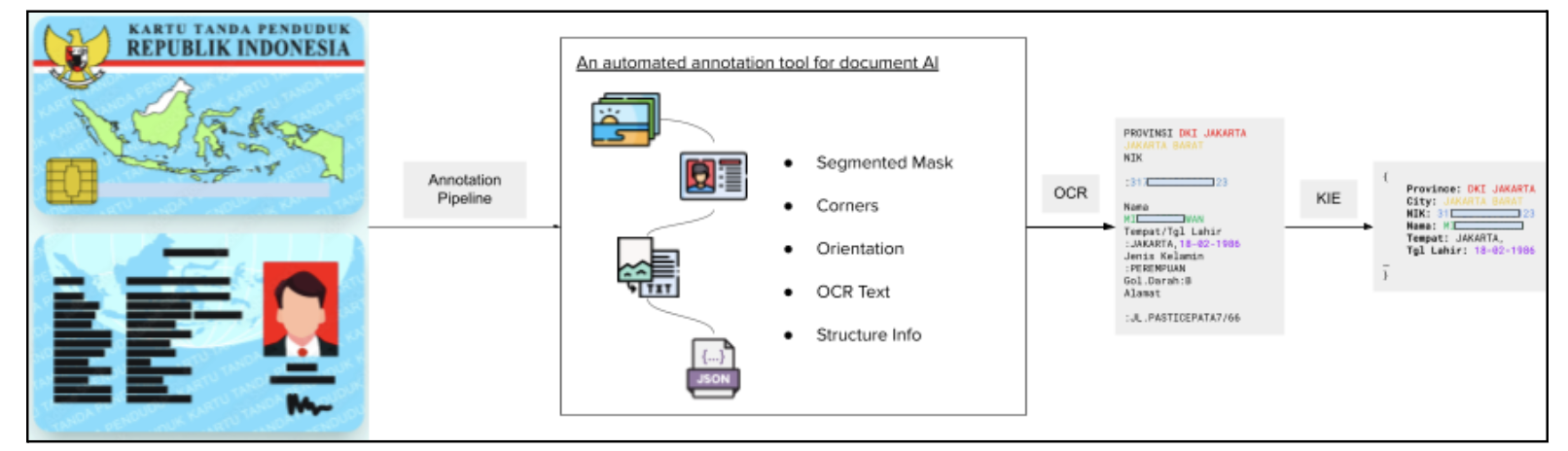
具体的处理流程图如下: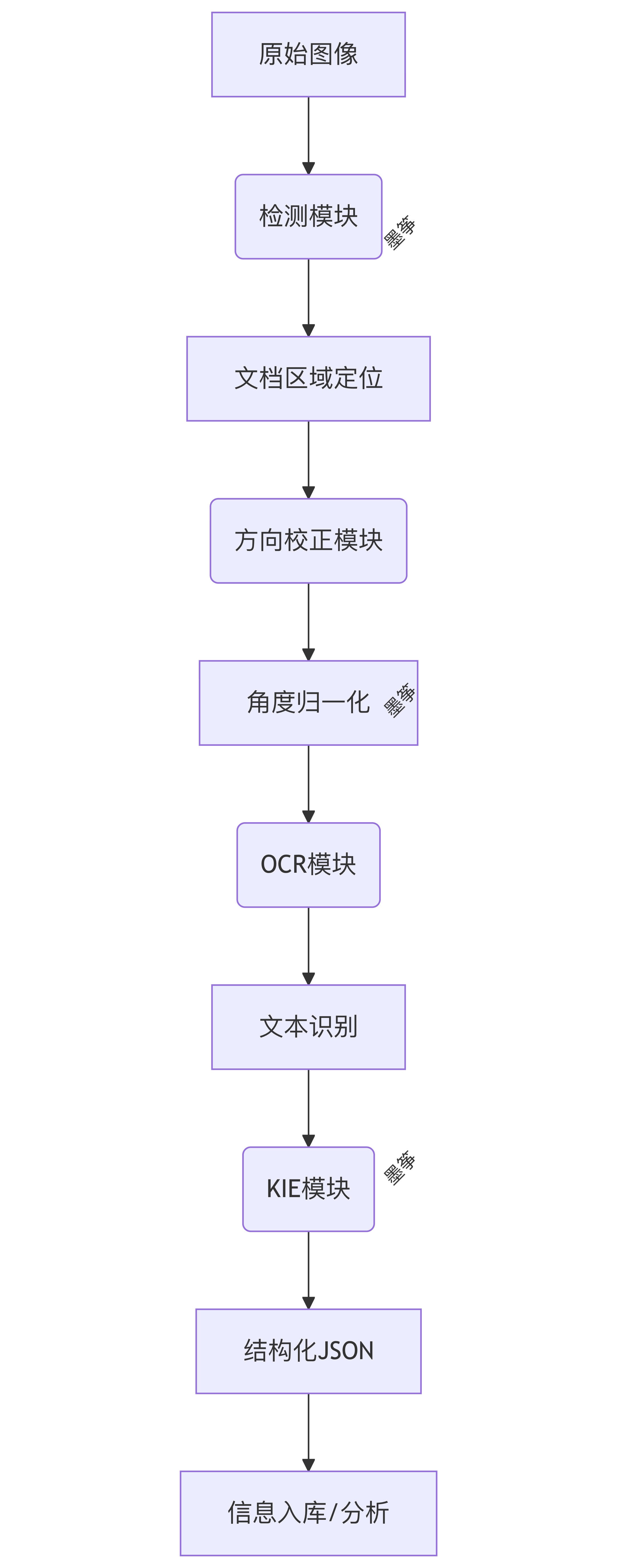
实验开始
有了标注数据集后就可以正式开始模型训练,Grab 的炼丹过程经历了如下三个阶段:
第一阶段:LoRa 降秩微调
Grab 首先采用低秩自适应(LoRA)技术对开源模型 Qwen2-VL 进行了微调。LoRA 的优势在于能对模型参数进行轻量化更新,显著降低算力资源需求,其原理如下所示:
在精选的多语言文档数据集上训练后,模型对拉丁语系文档表现出良好性能。经 LoRA 微调的 Qwen2-VL-2B 模型在印尼语文档上实现了较高的字段级准确率。
但仍存在以下局限:
- 非拉丁语系处理缺陷,泰语/越南语等复杂文字识别率偏低
- 复杂版式解析不足,对密集小文本的非结构化版式适应能力弱
这种拉丁语系和非拉丁语系的性能差异根源在于其文字特性的差异
| 语种 | 文字特性 | 错误案例 |
|---|---|---|
| 印尼语 | 拉丁字母+简单附加符 | 地址字段漏识别率<3% |
| 泰语 | 叠加字符/无空格分隔 | 单词切分错误率≈42% |
| 越南语 | 声调符号/复合字母 | 音调标记丢失率≈28% |
第二阶段:全量微调
在微调过程中 Grab 团队发现,尽管开源视觉大语言模型的预训练文本解码器通常覆盖了广泛的多语言语料,但其视觉编码器与联合训练阶段严重缺乏东南亚语言的视觉文本数据(当前视觉模型,如 CLIP 主要在英语图像-文本对训练,东南亚语言的图像文本数据,如泰语路牌/越南语收据等数据极度稀缺),从而导致模型无法针对东南亚语言建立从文字图像到语义的跨模态关联。技术矛盾如下图所示:

这种情况下 LoRA 这种只能小幅调整现有知识的模型微调就无法满足诉求,需要考虑进行全参数微调,重构视觉编码器的特征提取逻辑。
基于 LLaVA(大型语言视觉助手) 方法(来源于计算机视觉和模式识别领域的一篇论文,https://arxiv.org/abs/2304.08485),Grab 实施了如下图所示的训练策略,分为两个阶段执行: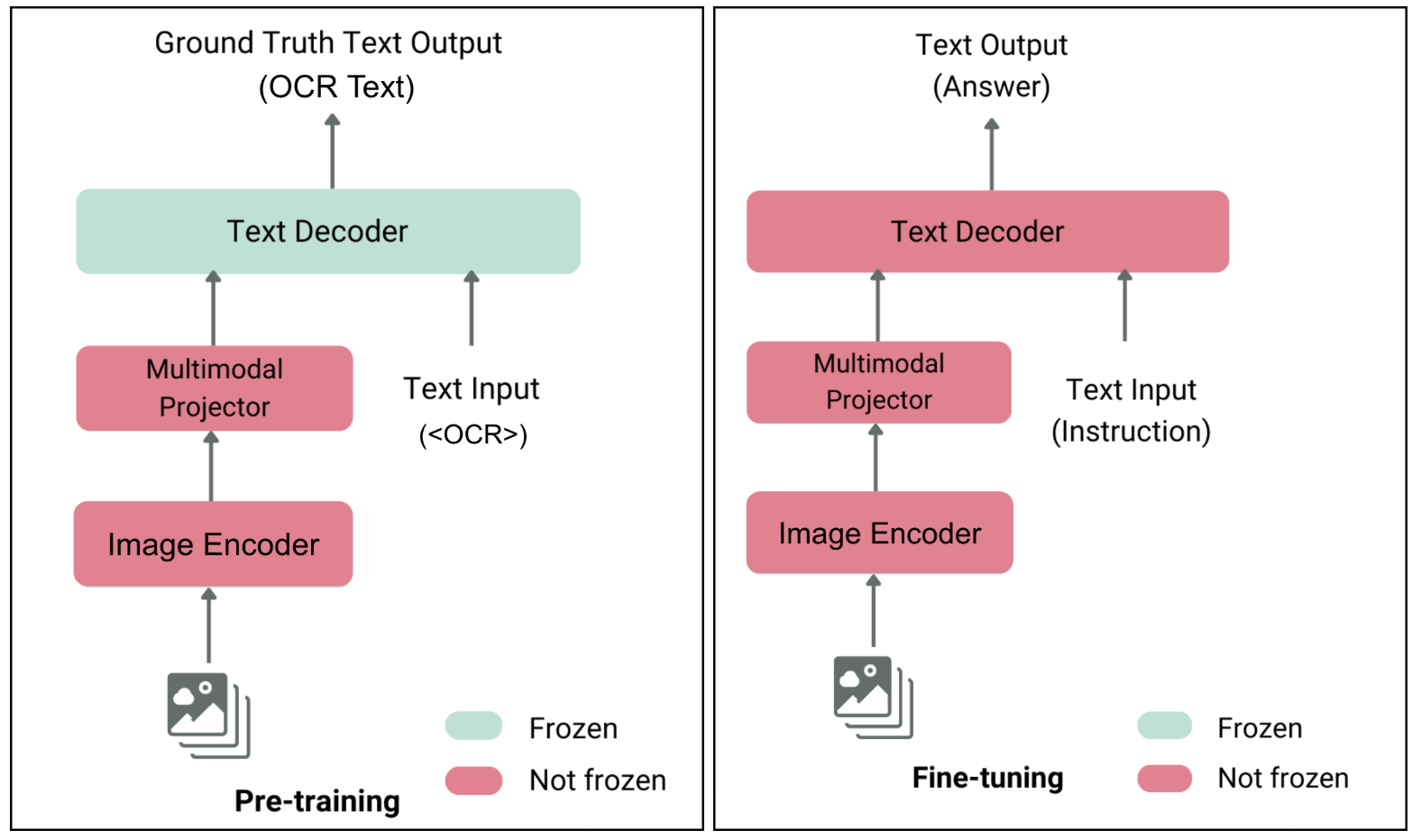
阶段1 - 持续预训练
使用前序为印尼语、泰语、越南语及英语创建的合成 OCR 数据集,专项精调模型视觉组件。此阶段使模型学习东南亚文字的独特视觉模式(如泰文叠加字符、越南语声调符号)。阶段2 - 全参数微调
基于任务专用文档数据,端到端微调整个模型体系——包括视觉编码器、投影层及语言模型。

全量微调后的实验结果如下图所示(pp 为百分点,口径为 OCR 字段级的准确度):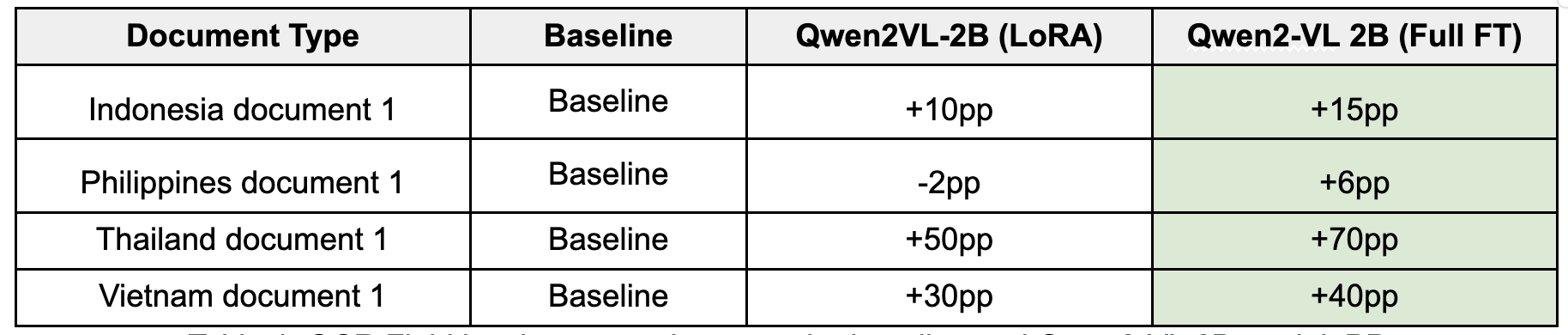
经过全参数微调的 Qwen2-VL 2B 模型实现了显著提升,在 LoRA 模型处理困难的文档类型上进步尤为突出:
- 泰语文档准确率较基准提升 +70个百分点
- 越南语文档准确率较基准提升 +40个百分点
第三阶段:从头构建一个轻量模型
尽管 Qwen2-VL 2B 模型取得了比较不错的效果,但全参数微调已逼近 GPU 算力极限。为优化资源使用并构建精准匹配需求的模型,Grab 决定从头开发约 1B 参数的轻量级视觉大模型。
Grab 采用的策略是融合多个模型中最优质的组件,包括:
- 视觉模块:继承 Qwen2-VL 2B 的高性能视觉编码器
- 语言模块:采用 Qwen2.5 0.5B 紧凑高效的语言解码器
- 连接层:定制自适应投影层实现多模态无缝协同

由此构建的约 1B 参数定制视觉大模型,在训练效率与部署成本上实现深度优化。新模型的训练采用四段渐进式流程:
阶段1 - 投影层对齐
训练新建投影层,确保视觉编码器与语言解码器实现有效跨模态通信。阶段2 - 视觉编码器增强
在海量公共多模态数据集上训练视觉编码器,覆盖视觉问答、通用 OCR 及图像描述等任务,夯实基础视觉理解能力。阶段3 - 语言专项视觉训练
使用两类合成 OCR 数据训练模型。此阶段缺失将导致非拉丁语文档性能断崖式下降(最高达 10%)。阶段4 - 任务集中微调
基于精选文档数据集,对定制 1B 参数模型实施全参数微调。
最终结果如下:
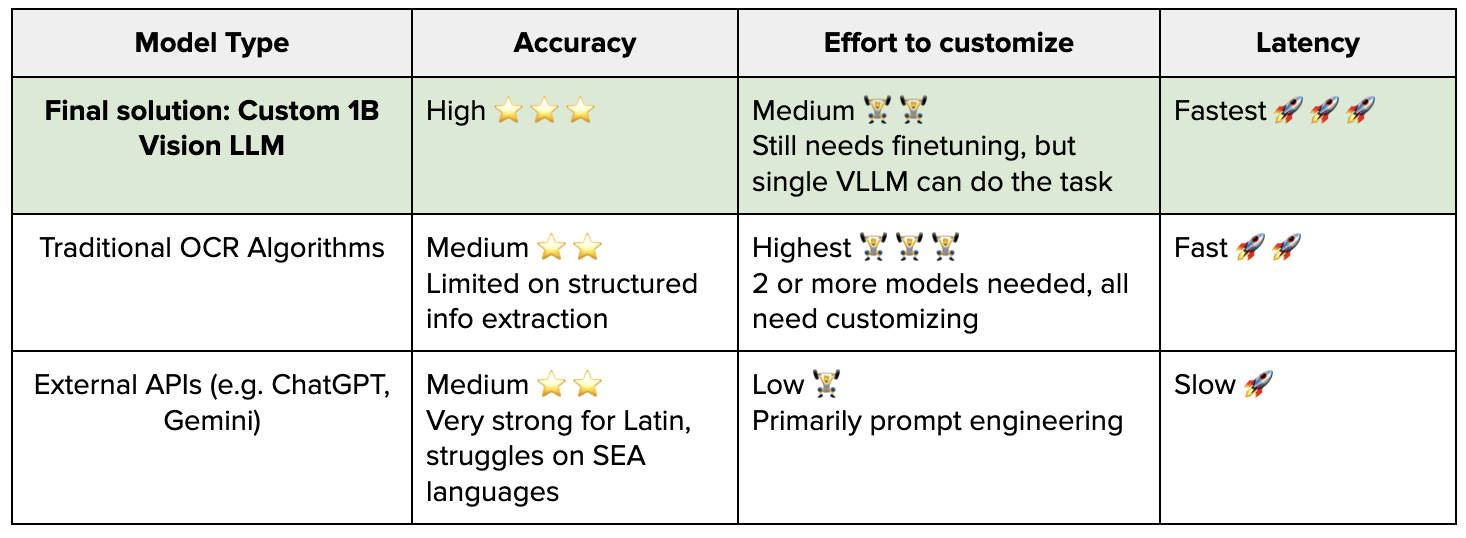
- 精度表现,模型达到与更大规模 2B 模型相当的精度,在多数文档类型上精度差距控制在 3 个百分点(pp)内。基于质量增强数据集训练后,模型展现出卓越的泛化能力。
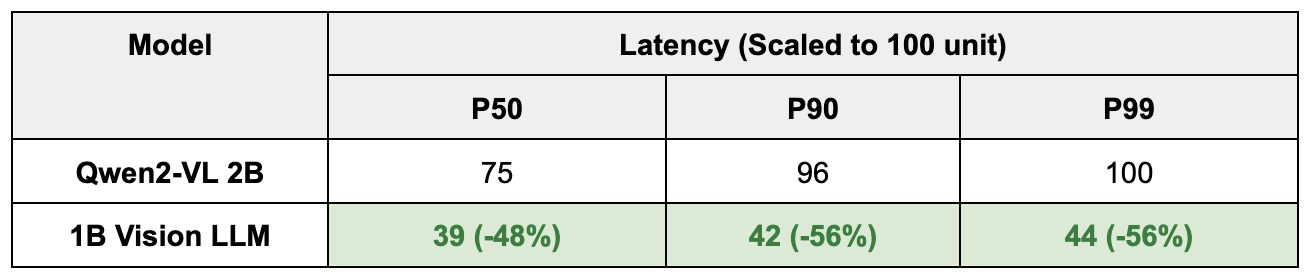
- 延迟表现,模型延迟显著优于 2B 模型、传统 OCR 模型及 chatGPT/Gemini 等外部模型 API。外部模型 API 的核心缺陷在于 P99 延迟可达 P50 的 3-4 倍,无法满足 Grab 大规模商业部署需求。具体效果如下所示:
关键结论与洞察
Grab 经过大量的实践得出的结论是:基于高质量数据的策略性训练可以使小型专用模型同时实现高效能与高效率,并由此得出几个关键洞察:
全参数微调优势显著
针对非拉丁语系专业领域,全参数微调全面超越 LoRA 等高效微调方法。轻量模型效果卓越
从头构建的约 1B 参数模型经充分训练,可达到接近业界顶尖水平,验证了定制架构价值。基础模型选择至关重要
采用原生支持目标语言的基础模型是成功关键。数据质量是核心竞争力
精细化的数据预处理与增强对实现稳定高精度具有决定性作用。原生分辨率处理能力带来变革
支持动态图像分辨率的模型能保持文本结构完整性,革命性提升 OCR 性能。
Grab 的实践证明:专用视觉大语言模型能够以单一高精度模型架构替代传统 OCR 流水线,为大规模文档处理开辟全新范式。
下一步规划
在持续升级视觉大语言模型能力的同时,Grab 的下一步计划是:
构建更智能的通用模型
研发基于思维链(Chain of Thought)技术的 OCR 与 KIE 模型,通过多步推理机制增强泛化能力,攻克更复杂的文档场景(如混合版式/模糊文本)。东南亚全域扩展
将支持范围拓展至 Grab 所覆盖的所有市场,为缅甸、柬埔寨等地区提供先进的文档处理能力。
结语
为了解决东南亚地区复杂的文本图像识别和准确高效的关键信息提取问题,Grab 进行了大模型降秩微调,全量微调以及完全自研模型的一系列实践,并最终取得了比较不错的业务效果,这也是 AI 用于解决实际业务问题的一例典型 case。笔者认为 AGI 的世界依然遥远,但轻量化,垂直化,结合业务特点定制化的小模型在当前阶段更有实际价值。
参考
Qwen2-VL:增强视觉语言模型在任意分辨率下的世界感知能力,https://doi.org/10.48550/arXiv.2409.12
基于视觉指令微调的改进基线模型,https://doi.org/10.48550/arXiv.2310.03744
SynthTIGER:面向高质量文本识别模型的合成文本图像生成器,https://doi.org/10.48550/arXiv.2107.09313
LlamaFactory:百种语言模型的统一高效微调框架
https://doi.org/10.48550/arXiv.2403.13372Grab 工程实践:https://engineering.grab.com/custom-vision-llm-at-grab
若你觉得我的文章对你有帮助,欢迎点击上方按钮对我打赏
扫描二维码,分享此文章